The problem
Marketing teams juggle a dozen tools and re-explain their brand to every AI prompt, with no memory and no visibility into what content costs.
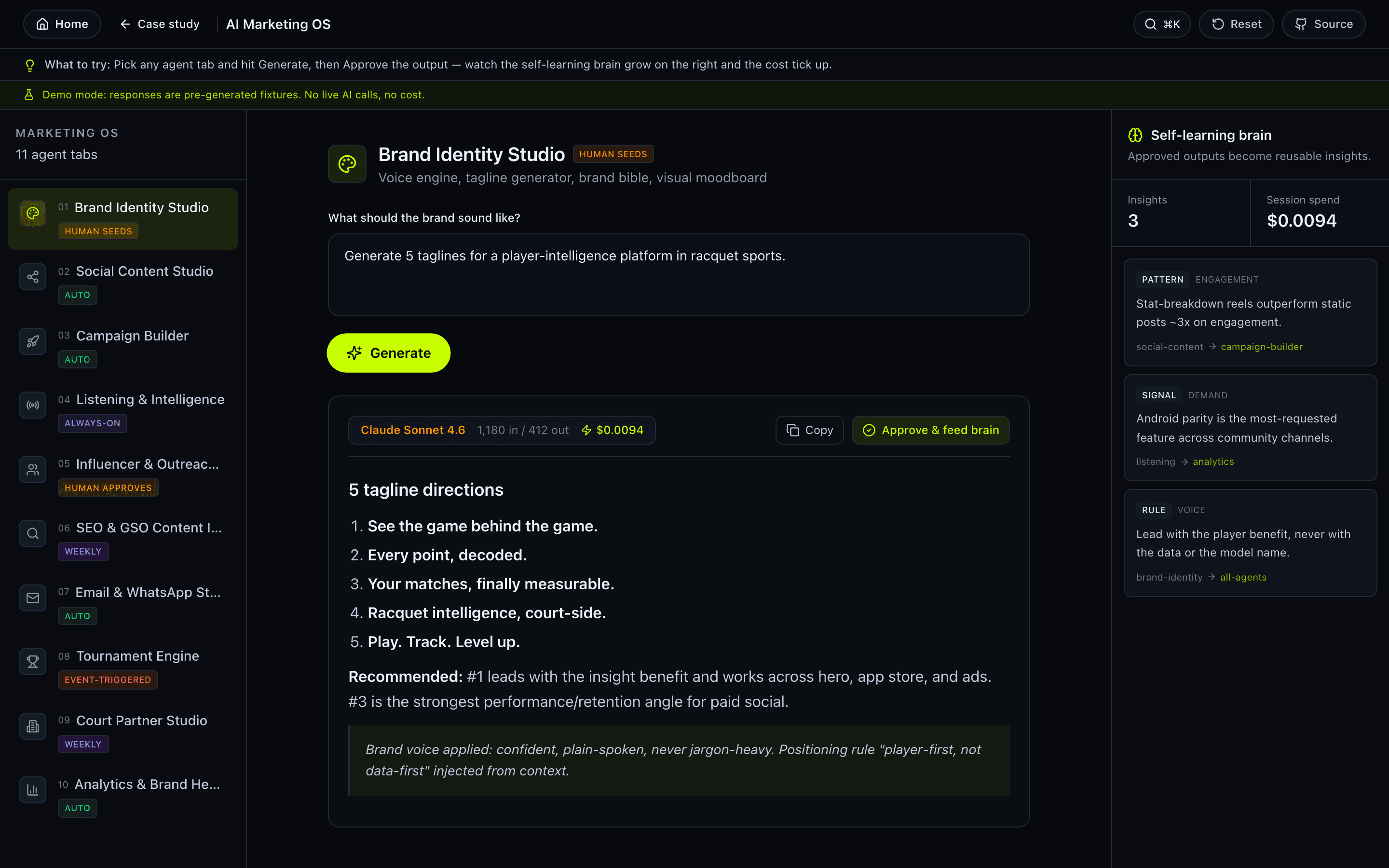
How it works
A tabbed workspace routes each request through brand-context injection, brain retrieval, Claude generation and cost logging. Approved outputs feed a Haiku extraction pass that grows the brain for future generations.
Architecture
Browser (Next.js App Router)
-> API routes /api/generate/[tab]
- Brand context injection
- Brain retrieval (top-k entries)
- Claude Sonnet 4.6 generation
- Cost logging to PostgreSQL
-> Post-approval: Claude Haiku extracts insights -> brainHighlights
- 11 specialized agent tabs across the full funnel: strategy, copy, email sequences, social content, ad creatives, SEO, launch plans and more.
- Self-learning brain: every approved output is analysed by Claude Haiku, which extracts reusable insights stored for future context.
- Real-time cost tracking per generation, per tab and system-wide.
- Brand context injection: voice, tone and positioning are prepended to every prompt automatically.
- Dual-LLM architecture: Sonnet generates, Haiku extracts and classifies for a 3x saving on extraction.
Key decisions & tradeoffs
Split work across two models: Sonnet generates, Haiku extracts.
Insight extraction is a cheaper, structured task — routing it to Haiku cut post-processing cost ~3x with no hit to the generated output.
A self-learning brain instead of a fixed system prompt.
A static prompt drifts and forgets; persisting approved insights and re-injecting them compounds quality and holds brand voice steady as the team scales.
Log cost per generation and feature, not just per API key.
Per-feature cost is what pricing and ROI decisions actually need; a single monthly bill hides where the money really goes.