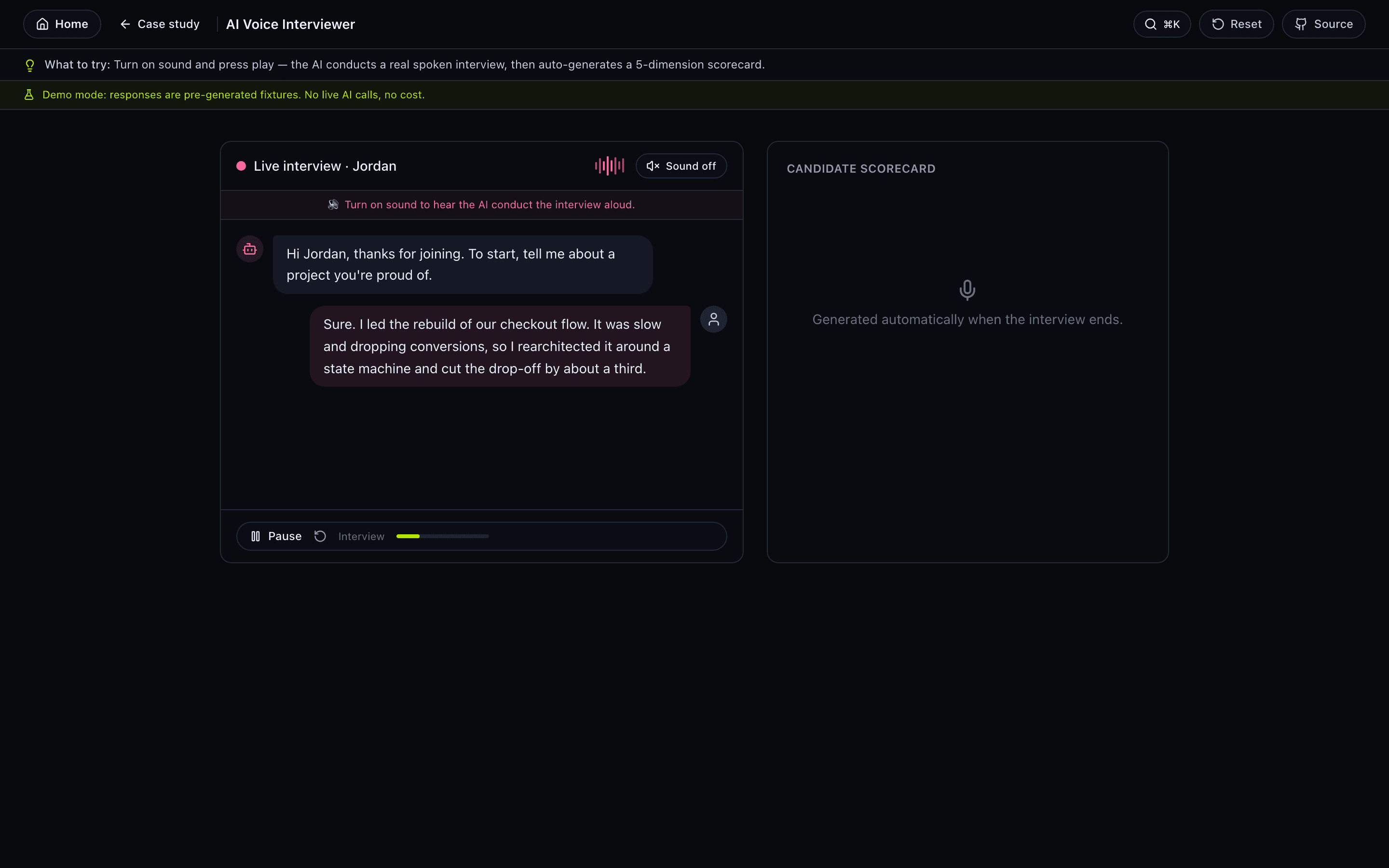
The problem
First-round screening interviews are a huge, repetitive time sink for hiring teams and are scheduled inconsistently across candidates.
How it works
A Pipecat pipeline streams candidate audio in, transcribes with Deepgram, sends text to Claude, and speaks the response back via Cartesia over Daily WebRTC. After the call, Claude scores the transcript into a structured scorecard.
Architecture
Candidate browser (Daily WebRTC)
<-> Next.js /interview/[token]
<-> Pipecat server (Python / FastAPI)
- Deepgram Nova-2 (STT)
- Claude Sonnet 4.6 (LLM)
- Cartesia Sonic (TTS)
-> Scorecard -> Admin dashboard + SlackHighlights
- Conducts full 20-minute structured first-round interviews autonomously.
- Scores each candidate across 5 dimensions: Communication, Role Fit, Motivation, Culture Fit, Problem Solving.
- Real-time voice loop: Deepgram STT feeds Claude, Claude responds via Cartesia TTS over Daily WebRTC.
- Structured rubric: Claude evaluates the transcript and emits a JSON scorecard per dimension.
- Admin dashboard to manage roles, view scorecards and replay sessions; Slack notifications push results instantly.
Key decisions & tradeoffs
Orchestrate the audio loop with Pipecat, not a hand-rolled pipeline.
Real-time turn-taking, interruptions and barge-in are deceptively hard; a proven framework removed weeks of plumbing and audio edge cases.
Score a fixed 5-dimension rubric as JSON, not free-text notes.
Comparable, consistent scorecards across candidates matter more than prose — and structured output makes the dashboard and Slack push trivial.
Optimise for latency over maximal answer quality.
In a live conversation, perceived lag beats a marginally better reply — a slow but perfect response just feels broken to the candidate.