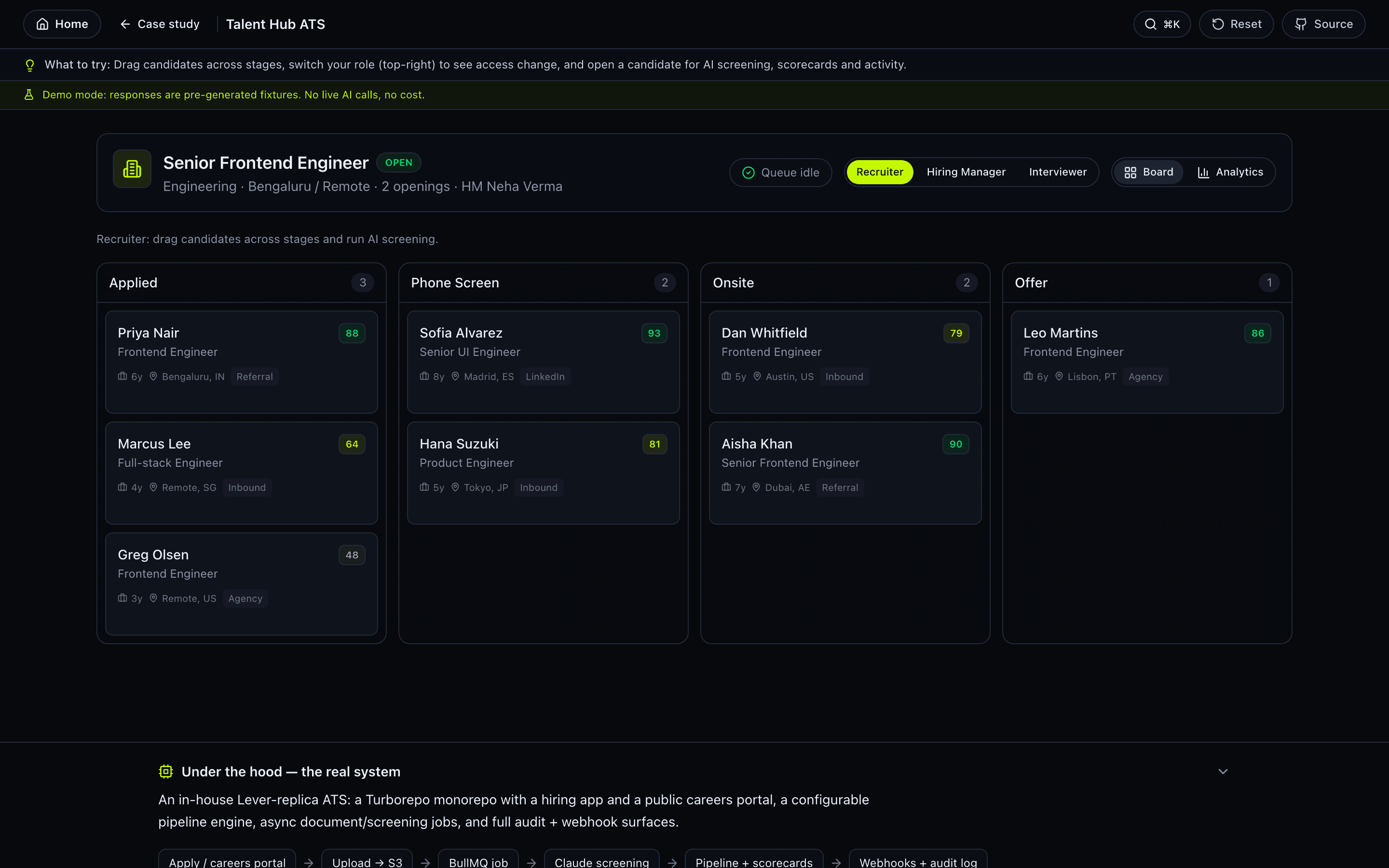
The problem
Hiring teams lose candidates in spreadsheets and screen resumes inconsistently, with no shared pipeline or audit trail.
How it works
A monorepo web app manages the candidate pipeline while background workers handle resume parsing and Claude-based scoring. Seed data ships with role-based test accounts for admin, recruiter, hiring manager and interviewer.
Architecture
Browser (Next.js 15) -> API routes (NextAuth) -> Prisma / PostgreSQL + BullMQ workers (Redis) -> Claude scoring, S3 (MinIO) docs, Slack notifications
Highlights
- AI resume screening: Claude evaluates uploaded resumes against job requirements and produces a structured fit score with reasoning.
- Drag-and-drop Kanban pipeline from Applied through Offer with stage-level analytics.
- Background job system (BullMQ + Redis) for async document processing, email and webhooks.
- EEO/OFCCP compliance tracking built into the pipeline.
- Turborepo monorepo with a shared Prisma schema, types and validators across the web app and workers.
Key decisions & tradeoffs
Run resume parsing and screening as async jobs, not inline.
LLM screening is slow; doing it in the request would block the UI and tie throughput to model latency. A BullMQ/Redis queue keeps the app responsive.
Make pipeline stages configurable templates, not hard-coded.
Every team's hiring flow differs; hard-coded stages guarantee a rewrite. Templating turned it into a real product instead of a one-off.
Evidence-first screening — scores must cite the rubric.
Unexplained AI scores get ignored or create bias/compliance risk; requiring reasoning makes them trustworthy and auditable.